Jede Anfrage an ChatGPT oder Claude kostet Tokens. Bei intensiver Nutzung summiert sich das schnell auf 50, 100 oder mehr Euro pro Monat. Gleichzeitig landen sensible Daten, wie Kundentexte, HR-Dokumente oder interne Notizen, auf fremden Servern. Mit Ollama und n8n löst du beide Probleme gleichzeitig: KI-Workflows laufen vollständig auf deinem eigenen Rechner, ohne Abrechnungsüberraschungen und ohne dass ein Byte dein System verlässt.
In diesem Guide zeige ich dir, wie du Ollama mit deiner bestehenden n8n-Docker-Installation verbindest. Du lernst, welches Modell für welchen Use Case passt, und bekommst vier fertige Workflows für die Praxis.
- Ollama installieren:
curl -fsSL https://ollama.com/install.sh | sh - Erstes Modell laden:
ollama pull mistral - n8n-Credential anlegen, URL:
http://host.docker.internal:11434 - Ollama Model Node in deinen Workflow ziehen und loslegen
Inhaltsverzeichnis
Was ist Ollama und warum macht es Sinn?
Ollama ist ein lokaler LLM-Server. Du installierst ihn auf deinem Rechner, lädst ein Sprachmodell aus der Open-Source-Bibliothek herunter und verbindest n8n dann über eine API, genau wie mit der OpenAI-API. Der entscheidende Unterschied: Alles passiert lokal, auf deinem eigenen Rechner. Kein Internetzugriff, keine Abrechnung pro Token, keine fremden Server.
Ollama unterstützt alle gängigen Large-Language-Models: Mistral, Llama, Phi, Qwen und viele weitere. n8n verbindet sich mit Ollama über den Ollama Model Node und nutzt das lokal laufende Modell als KI-Motor für deine Workflows. Das Setup klingt komplex, ist aber in unter 10 Minuten erledigt.
Zusammen ergeben n8n und Ollama eine vollständige lokale Automatisierungsplattform, die ohne externe KI-Dienste auskommt. Ideal für alle, die sensible Daten im eigenen System behalten müssen oder die laufenden Kosten für KI-APIs auf null senken wollen.
- Keine API-Kosten
- Daten verlassen nie dein System
- DSGVO-konform ab Werk
- Offline-fähig
- Unbegrenzte Anfragen
- Hardware-Anforderungen (RAM)
- Qualität unter GPT-4 / Claude 3
- Kein Bild- oder Audio-Input
- Tool-Calls in n8n eingeschränkt
Für viele alltägliche Automatisierungsaufgaben, wie Text klassifizieren, zusammenfassen, übersetzen oder strukturieren, reicht ein lokales 7B-Modell problemlos aus.
| Kriterium | Ollama (lokal) | Cloud-APIs (OpenAI etc.) |
|---|---|---|
| Kosten | Keine laufenden Kosten | Per Token abgerechnet |
| Datenschutz | Daten verlassen nie das System | Daten gehen an externe Server |
| Qualität | Gut für Routineaufgaben | Besser für komplexe Aufgaben |
| Setup | Ollama installieren, Modell laden | API-Key, sofort nutzbar |
| Skalierung | Begrenzt durch eigene Hardware | Beliebig skalierbar |
| DSGVO | Kein Problem | Auftragsverarbeitung nötig |
Was brauche ich und wie installiere ich Ollama?
Hardware-Anforderungen
Die wichtigste Variable ist der Arbeitsspeicher. Je nach Modellgröße brauchst du 4 bis 16 GB RAM. Ein 7B-Modell wie Mistral läuft mit 8 GB, komfortabler mit 16 GB. Kleinere Modelle kommen bereits mit 4 GB aus. Eine dedizierte GPU ist nicht nötig, beschleunigt die Antwortzeiten aber erheblich, besonders auf Apple Silicon (M1 bis M4).
| Modell | Größe | RAM min. | Deutsch | Empfehlung |
|---|---|---|---|---|
| Mistral 7B | 4,1 GB | 8 GB | gut | Einstieg, Allgemein |
| Llama 3.2 3B | 2,0 GB | 4 GB | mittel | Ältere Hardware |
| Llama 3 8B | 4,7 GB | 8 GB | gut | Vielseitig |
| Phi-3.5 Mini | 2,2 GB | 4 GB | gut | Wenig RAM, schnell |
| Qwen2.5 7B | 4,4 GB | 8 GB | sehr gut | Deutsche Texte |
Für diesen Guide verwenden wir Mistral. Es ist schnell, gut auf Deutsch und deckt die meisten Anwendungsfälle ab. Wenn du intensiv mit deutschen Texten arbeitest, ist Qwen2.5 7B eine starke Alternative. Weitere Modelle findest du in der offiziellen Ollama-Bibliothek unter ollama.com/library.
Ollama installieren
Auf macOS und Linux genügt ein einziger Befehl im Terminal:
# Ollama installieren curl -fsSL https://ollama.com/install.sh | sh
Unter Windows lädst du das Installationsprogramm direkt von ollama.com/download herunter und führst es aus.
Anschließend lädst du Mistral herunter. Der erste Download ist je nach Internetverbindung 4-5 Minuten langsam, danach läuft alles lokal:
# Mistral 7B herunterladen (4,1 GB) ollama pull mistral # Installierte Modelle anzeigen ollama list

Wenn ollama list dein Modell anzeigt, ist Ollama einsatzbereit.
Wie verbinde ich n8n mit Ollama?
Hier versteckt sich der häufigste Anfängerfehler. Wenn n8n in Docker läuft und Ollama direkt auf deinem Rechner (dem Host), dann ist localhost aus Docker-Perspektive nicht dein Rechner, sondern der Container selbst. Die Verbindung schlägt also fehl.
Der Ollama Model Node erwartet unter Credentials eine Base URL, die auf den laufenden Ollama-Prozess zeigt. Die richtige Adresse hängt davon ab, wie dein Setup aufgebaut ist.
Wenn n8n in Docker läuft und Ollama direkt auf dem Rechner:
- Ollama muss auf allen Netzwerk-Interfaces lauschen. Dazu im Terminal starten mit:
OLLAMA_HOST=0.0.0.0 ollama serve - URL in n8n: Nicht localhost, sondern die lokale IP des Rechners verwenden, z.B.
http://192.168.178.39:11434. Eigene IP herausfinden mit:ifconfig | grep "inet " - Ollama ebenfalls in Docker: URL lautet
http://<container-name>:11434
Credential in n8n anlegen
http://localhost:11434, was für Docker-Setups falsch ist).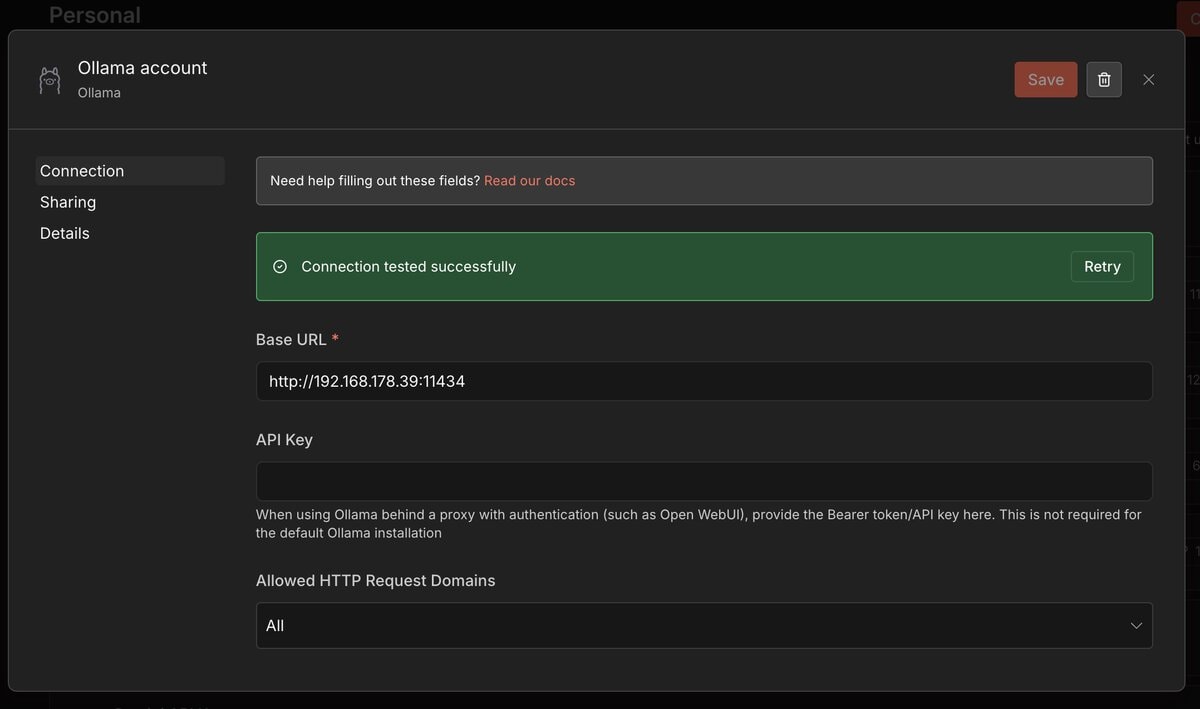
Erster Test: Lokaler KI-Chatbot in 5 Minuten
Der einfachste Weg, die Verbindung zu testen, ist ein Chat-Workflow. Du brauchst dafür nur drei Nodes. Das Ergebnis: ein lokaler KI-Assistent, der vollständig auf deinem eigenen Rechner läuft und sofort auf Fragen antwortet.
mistral eintragen.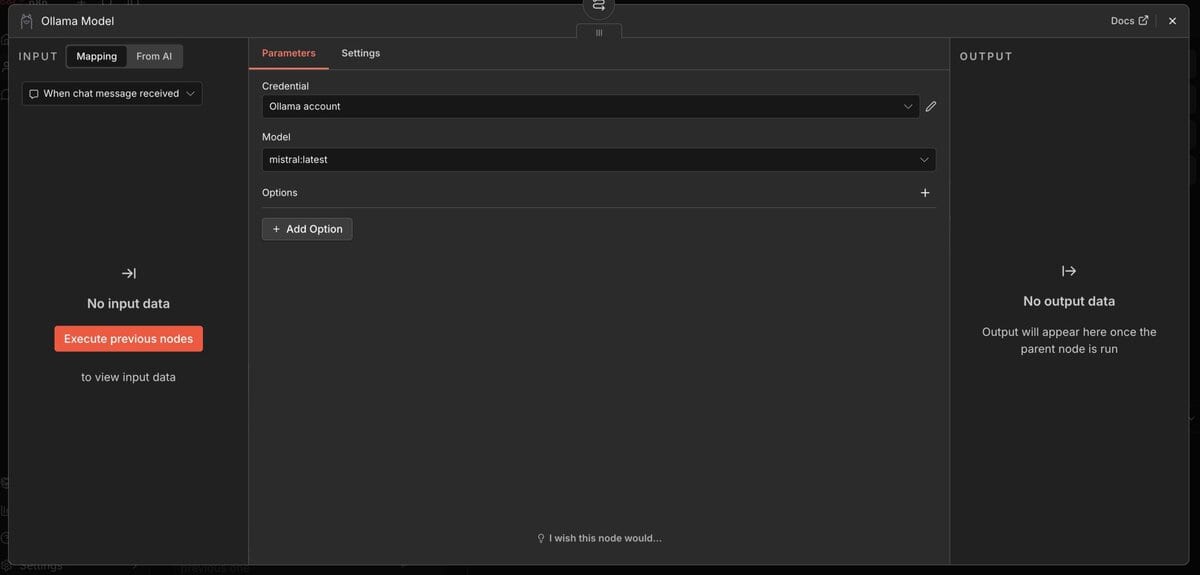
Der AI Agent Node unterstützt Tool-Calls mit Ollama derzeit nicht zuverlässig. Für stabile Workflows nutze immer den Basic LLM Chain Node als Ausgangspunkt. Tool-Calls kannst du manuell über nachgelagerte Nodes einbauen. Der Ollama Model Node bietet außerdem drei Parameter zur Feinsteuerung: Temperature (Kreativität), Top K (Tokenauswahl) und Top P (Wahrscheinlichkeitsschwelle).
Wenn Mistral antwortet, funktioniert die Verbindung. Wer tiefer in die Node-Logik von n8n einsteigen will, findet dazu alles im Artikel n8n Nodes erklärt. Jetzt zu den Praxis-Workflows.
Welche Workflows kann ich mit Ollama und n8n bauen?
Die folgenden vier Workflows zeigen typische Anwendungsfälle, die besonders von der lokalen Verarbeitung profitieren: sensible Dokumente, interne Daten, DSGVO-kritische Texte.
Dokumente lokal zusammenfassen
Sensible PDFs, Verträge oder interne Reports werden nie in die Cloud hochgeladen. Der Workflow liest den Textinhalt, schickt ihn an Mistral und gibt eine strukturierte Zusammenfassung zurück.
Prompt-Vorlage: „Fasse folgenden Text in 5 Stichpunkten auf Deutsch zusammen: {{ $json.text }}“
E-Mail-Eingang automatisch klassifizieren
Mistral liest eingehende E-Mails und ordnet sie Kategorien zu, zum Beispiel „Bestellung“, „Support“, „Beschwerde“ oder „Spam“. Das Ergebnis steuert den weiteren Workflow-Verlauf per IF-Node.
Prompt-Vorlage: „Klassifiziere die E-Mail als eine von: Bestellung, Support, Beschwerde, Sonstiges. Antworte nur mit der Kategorie: {{ $json.subject }} – {{ $json.body }}“
Interne Texte auf Deutsch prüfen und verbessern
Mitarbeiter-E-Mails, Produktbeschreibungen oder Blogdrafts werden lokal auf Rechtschreibung, Ton und Klarheit geprüft. Besonders nützlich, wenn Texte Betriebsgeheimnisse enthalten.
Tipp: Für deutsche Texte liefert Qwen2.5 7B hier spürbar bessere Ergebnisse als Mistral.
Strukturierte Daten aus Freitext extrahieren
Aus unstrukturierten Texten, wie Kundenfeedback oder Bewerbungsunterlagen, extrahiert Mistral gezielt Felder im JSON-Format. Die Ausgabe fließt direkt in Google Sheets oder eine Datenbank.
Prompt-Vorlage: „Extrahiere Name, E-Mail und Hauptanliegen als JSON aus folgendem Text: {{ $json.text }}“
Warum Ollama + n8n die DSGVO-sicherste KI-Lösung ist
Bei Cloud-KI-Diensten gibt es immer eine kritische Frage: Wo werden die Daten verarbeitet und wer sieht sie? Bei Ollama ist die Antwort eindeutig. Die Daten verlassen deinen Server nicht.
Das hat konkrete Konsequenzen für den DSGVO-Alltag:
- Keine Auftragsverarbeitungsverträge nötig mit KI-Anbietern, weil keine Daten übertragen werden
- Kein Drittlandtransfer, keine US-Server, keine Privacy-Shield-Diskussionen
- Volle Kontrolle über Logs, es werden keine Anfragen an externe Anbieter gespeichert
- Auditierbar, du kannst nachweisen, dass Kundendaten das System nie verlassen haben
In Kombination mit n8n selbst gehostet auf deinem eigenen PC sowie Ollama hast du eine vollständig souveräne KI-Automatisierungsplattform. Was das konkret für dein n8n-Setup bedeutet, erkläre ich ausführlich im Artikel n8n und DSGVO: So betreibst du n8n rechtskonform.
Ein Punkt bleibt: Lokale Modelle wie Mistral sind schwächer als GPT-4 oder Claude 3 Opus. Für einfache Klassifizierungen, Zusammenfassungen und Extraktionen reicht die Qualität aber problemlos aus. Bei komplexen Aufgaben wie kreativen Texten oder mehrschrittigem Reasoning ist Cloud-KI weiterhin überlegen.
Häufige Fehler und wie du sie behebst
Lösung: URL in der Ollama Credential auf
http://host.docker.internal:11434 ändern. Auf Linux zusätzlich in der docker-compose.yml unter dem n8n-Service eintragen:
extra_hosts: - "host.docker.internal:host-gateway"
Lösung: Im Terminal
ollama list ausführen und prüfen, wie das Modell exakt heißt. Dann den Namen im Ollama Model Node entsprechend anpassen, zum Beispiel mistral statt mistral:latest.
Lösung: Ein kleineres Modell verwenden, zum Beispiel
ollama pull phi3.5 statt Mistral. Auf Apple Silicon (M1/M2/M3) nutzt Ollama automatisch die GPU-Beschleunigung.
Lösung: Für stabile Ergebnisse auf Basic LLM Chain umsteigen und Tools manuell als nachgelagerte Nodes einbauen.
Lösung: Auf Linux systemd aktivieren:
sudo systemctl enable ollama. Auf macOS startet Ollama nach der Installation automatisch als Hintergrund-App.
Für wen lohnt sich n8n + Ollama?
n8n mit Ollama ist kein Ersatz für GPT-4 oder Claude, wenn es um kreative oder komplexe Aufgaben geht. Aber als DSGVO-sichere, kostenfreie Alternative für Routineaufgaben ist die Kombination kaum zu schlagen: keine laufenden Kosten, volle Datenkontrolle, keine Abhängigkeit von externen Diensten.
Besonders sinnvoll ist das Setup für alle, die sensible Daten automatisieren wollen, ohne sie an externe KI-Anbieter zu übertragen. Wer n8n ohnehin selbst hostet, hat damit eine vollständige lokale KI-Plattform.
Starte mit Mistral, teste die vier Workflows aus diesem Artikel und schau, wo sich lokal laufende Sprachmodelle in deine Automatisierungen einfügen. Den nächsten Schritt, nämlich n8n DSGVO-konform zu betreiben, erklärt der Artikel n8n und DSGVO: Vollständige Anleitung 2026. Wer komplexere KI-Agenten mit Tools bauen will, findet dazu den Einstieg im Artikel n8n KI-Agenten bauen.
Mehr zum n8n-Ökosystem findest du auf der n8n Übersichtsseite.
Häufige Fragen zu n8n und Ollama
Funktioniert Ollama auch ohne Grafikkarte?
Ja. Ollama läuft vollständig auf der CPU. Die Antwortzeiten sind langsamer, aber für Automatisierungen, bei denen keine Echtzeit-Antwort nötig ist, völlig akzeptabel. Auf Apple Silicon (M1–M4) nutzt Ollama automatisch die integrierte GPU, was die Performance erheblich verbessert.
Welches Ollama-Modell eignet sich am besten für Deutsche Texte?
Für deutschsprachige Aufgaben empfehle ich Qwen2.5 7B. Es ist speziell auf mehrsprachige Texte trainiert und liefert bei deutschen Texten spürbar bessere Ergebnisse als Mistral oder Llama 3. Mistral ist ein guter Allrounder und für den Einstieg die einfachere Wahl.
Kann ich mehrere Modelle gleichzeitig nutzen?
Ja. Du kannst beliebig viele Modelle herunterladen und in verschiedenen n8n‑Workflows unterschiedliche Modelle einsetzen. Aktiv ist immer nur das Modell, das gerade eine Anfrage verarbeitet. Ollama lädt Modelle bei Bedarf in den RAM und entlädt sie nach einer Inaktivitätsphase automatisch.
Ist Ollama wirklich DSGVO‑konform?
Da Ollama komplett lokal läuft und keine Daten nach außen überträgt, gibt es aus DSGVO‑Sicht kein Übertragungsproblem. Wichtig ist, dass auch n8n datenschutzkonform betrieben wird (z. B. auf einem eigenen Server in Deutschland). Details: n8n-dsgvo.
Kann ich Ollama auch auf einem Server oder NAS betreiben?
Ja. Ollama lässt sich auf jedem Linux‑Server installieren, auch auf NAS‑Systemen wie Synology oder TrueNAS Scale. n8n verbindet sich über die lokale Netzwerk‑IP (z. B. http://192.168.1.100:11434). Vorteil: alle Daten bleiben im eigenen Netzwerk, und mehrere Dienste können das Modell nutzen.















