


Dein KI-Agent gibt falsche Antworten, weil er deine Dokumente, deine Preisliste oder deine internen Abläufe schlicht nicht kennt. Das ist kein Fehler des Modells, sondern ein Informationsproblem. RAG löst es. Und n8n macht den Aufbau eines RAG-Systems so einfach wie das Zusammenstecken von Bausteinen, ohne eine einzige Zeile Code.
In diesem Guide bauen wir ein vollständiges n8n RAG System: von den Rohdaten bis zum fertigen KI-Agenten, der präzise Antworten auf Basis deiner eigenen Inhalte liefert.
* Dieser Artikel enthält Affiliate-Links. Bei einem Kauf über diese Links erhalten wir eine Provision ohne Mehrkosten für dich.
- Datenquelle verbinden (Google Drive, PDF oder Website)
- Text aufteilen und als Embeddings in einen Vector Store laden (Ingestion-Workflow)
- Retrieval-Workflow bauen: Anfrage → passende Chunks suchen → KI-Agent antwortet
- Chat-Interface testen und Ergebnisse schrittweise verbessern
Inhaltsverzeichnis
Was ist RAG und warum braucht dein KI-Agent das?
Stell dir vor, du fragst einen hochqualifizierten Berater nach deinen spezifischen Vertragskonditionen. Sehr kompetent, zweifellos. Er hat deinen Vertrag aber nie gelesen. Die Antwort wird plausibel klingen und trotzdem falsch sein. Genau so verhält sich ein Sprachmodell ohne Zugang zu deinen eigenen Daten.
RAG steht für Retrieval-Augmented Generation. Das Prinzip ist einfach: Bevor das KI-Modell antwortet, durchsucht es eine Wissensdatenbank nach den relevantesten Textausschnitten zu deiner Frage. Diese Ausschnitte landen als Kontext im Prompt. Das Modell antwortet jetzt nicht aus dem Gedächtnis, sondern auf Basis deiner echten Inhalte.
Das Ergebnis ist ein AI-Agent, der:
- Fragen zu deinen Dokumenten präzise beantwortet, ohne zu halluzinieren
- immer auf dem neuesten Stand ist, weil die Wissensdatenbank aktualisierbar ist
- nur antwortet, was tatsächlich in deinen Unterlagen steht
Wie funktioniert RAG in n8n genau?
Ein n8n RAG System besteht aus zwei getrennten Workflows, die du einmal aufbaust und dann unabhängig betreibst.
Phase 1: Ingestion (läuft einmalig oder bei Datenänderungen)
Phase 2: Retrieval (läuft bei jeder Nutzeranfrage)
Die wichtigsten n8n-Nodes für ein RAG-System:
- Default Data Loader oder Google Drive Node: Dokumente einlesen
- Text-Splitter: Dokumente in überschaubare Chunks aufteilen
- Embeddings (OpenAI, Cohere oder lokal via Ollama): Text in Zahlenvektoren umwandeln
- Vector Store (Supabase, Qdrant, Pinecone): Vektoren speichern und durchsuchen
- AI-Agent mit Vector Store Tool: Fragen beantworten auf Basis der gespeicherten Chunks
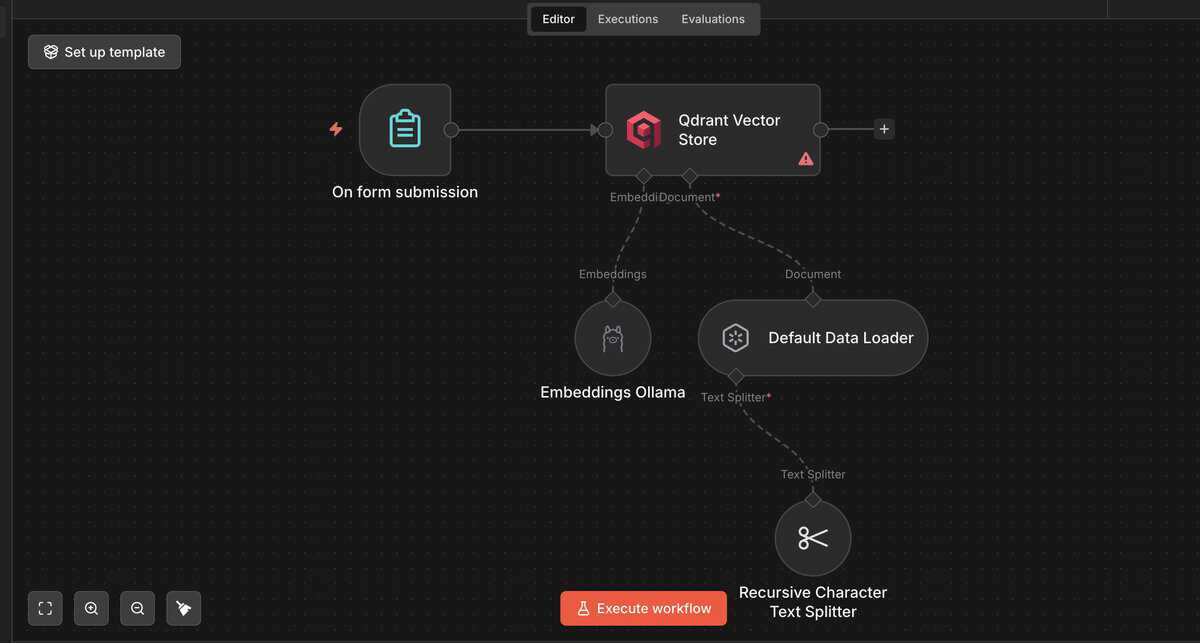
n8n Ingestion-Workflow: Dokumente laden, aufteilen, als Vektoren speichern
Welcher Vector Store ist der richtige für dich?
Der Vector Store ist das Herzstück deines RAG-Systems. Er speichert die Embeddings und macht sie durchsuchbar. Die Wahl hat direkte Auswirkungen auf Kosten, Aufwand und Datenschutz.
| Supabase | Qdrant (lokal) | Pinecone | Postgres + pgvector | |
|---|---|---|---|---|
| Einstieg | Sehr einfach | Mittel | Einfach | Mittel |
| Kosten | Kostenlos (Free) | Kostenlos | Ab ~$8/Monat | Kostenlos |
| DSGVO | EU-Region wählbar | 100 % lokal | US-Server | Selbst kontrolliert |
| n8n-Integration | Nativer Node | Nativer Node | Nativer Node | Nativer Node |
| Empfehlung | Einsteiger | Datenschutz | Nicht empfohlen | Fortgeschrittene |
Für den Einstieg ist Supabase die erste Wahl: kostenloser Free-Plan, EU-Server verfügbar, nativer n8n-Node, pgvector erledigt die Vektorsuche intern. Wer sensible Daten verarbeitet oder komplett lokal bleiben will, greift zu Qdrant via Docker. Den vollständigen Server-Setup erklärt der Artikel n8n Self-Hosting. Pinecone ist teurer und läuft auf US-Servern.
Wie baust du ein n8n RAG System Schritt für Schritt?
Das Setup besteht aus zwei Workflows: dem Ingestion-Workflow zum Befüllen des Vector Store und dem Retrieval-Workflow für den laufenden Betrieb.
Ingestion-Workflow
-
Datenquelle verbinden. Für Dokumente aus Google Drive nimmst du den Google Drive Node (Trigger: bei neuer Datei oder manuell). Für PDFs funktioniert der HTTP Request Node mit anschließendem Binary Data Node. Für Website-Inhalte eignet sich der HTTP Request Node mit HTML-Extraktion.
-
Text Splitter konfigurieren. Der Recursive Character Text Splitter ist für die meisten Anwendungsfälle die beste Wahl. Die optimale Chunk-Größe hängt vom Dokumenttyp ab: FAQ-Seiten 200–300 Tokens (kurze, prägnante Antworten), Produkthandbücher und längere Berichte 600–800 Tokens, gemischter Website-Content 400–500 Tokens als guter Standardwert. Overlap von 50–100 Tokens immer aktivieren, damit du keinen Kontext an den Chunk-Grenzen verlierst.
-
Embeddings wählen. OpenAI text-embedding-3-small liefert sehr gute Ergebnisse für deutschsprachige Texte bei geringen Kosten. Wer lokal bleiben will, nutzt Ollama mit nomic-embed-text. Wichtig: Im Ingestion- und Retrieval-Workflow muss dasselbe Embedding-Modell verwendet werden.
-
Vector Store Node verbinden. Supabase Vector Store Node einfügen, Collection Name vergeben, Embedding-Knoten anschließen. Beim ersten Durchlauf erstellt n8n die Tabelle automatisch. Der Node speichert die Chunks zusammen mit ihren Vektoren.
-
Ingestion-Workflow ausführen. Für die erste Befüllung einmalig manuell starten. Für automatische Updates einen Schedule Trigger oder Google Drive Watch Trigger einbauen.
Retrieval-Workflow
-
Chat Trigger Node als Einstieg. Der Chat Trigger öffnet ein einfaches Chat-Interface direkt in n8n. Alternativ funktioniert ein Webhook für die Integration in externe Tools.
-
AI Agent Node einfügen. Als Tool den Vector Store Retriever verbinden. Das Sprachmodell kann das Tool selbst aufrufen, wenn eine Frage nach Dokumenteninhalten kommt. Als Sprachmodell ist GPT-4o-mini ein gutes Preis-Leistungs-Verhältnis für die meisten RAG-Anwendungen. Claude Haiku antwortet schneller bei ähnlicher Qualität. GPT-4o oder Claude Sonnet lohnen sich nur, wenn die Antworten bei komplexen Fragen nicht präzise genug sind.
-
Vector Store Retriever konfigurieren. Denselben Supabase- oder Qdrant-Node einbinden, den du beim Ingestion-Workflow verwendet hast. Top-K auf 3 bis 5 setzen: So bekommt der AI Agent die 3 bis 5 relevantesten Chunks als Kontext.
-
Memory Node für Gesprächskontext. Ohne Memory-Node beantwortet der Agent jede Frage isoliert, ohne Erinnerung an vorherige Nachrichten. Den Window Buffer Memory Node einbinden und mit dem AI Agent verbinden. Standard: 10 Nachrichten Puffer. Das reicht für die meisten Chat-Anwendungen.
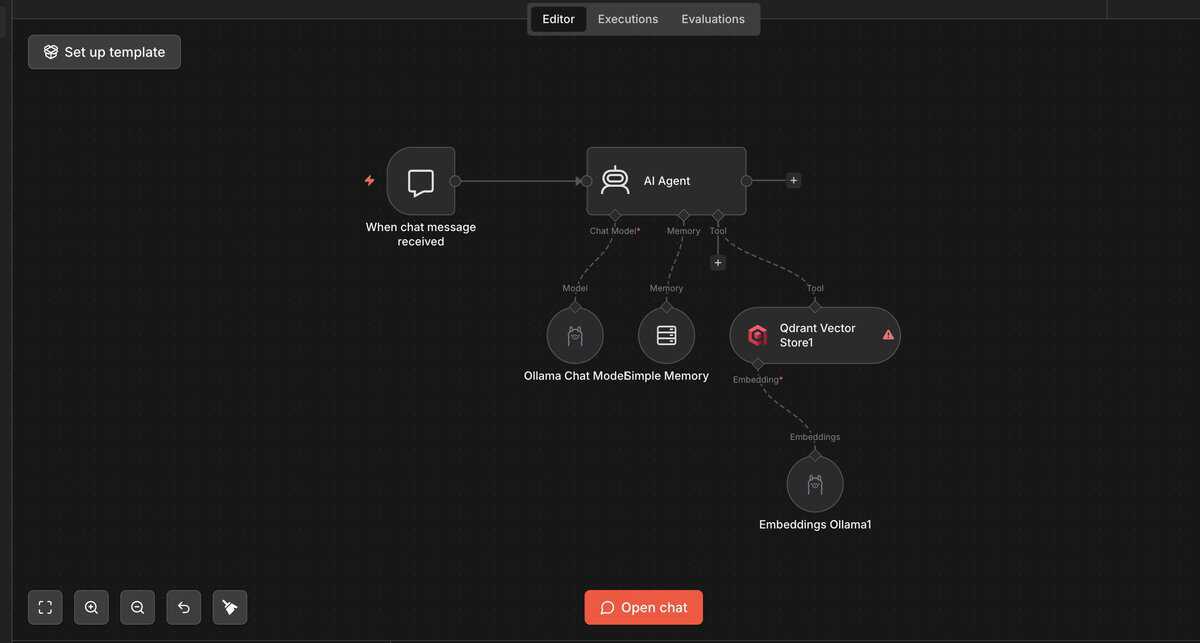
n8n Retrieval-Workflow: Eingehende Fragen durchsuchen den Vector Store und der AI Agent antwortet
Drei n8n RAG Anwendungsfälle für die Praxis
FAQ-Chatbot aus eigener Dokumentation
Du hast ein Produkthandbuch oder eine FAQ-Sammlung. Lade die Dokumente in den Vector Store und verbinde einen Chat-Interface-Trigger. Kunden oder Mitarbeiter bekommen präzise Antworten direkt aus deinen Inhalten, ohne dass du jede Frage manuell beantworten musst.
Persönliche Recherche-Datenbank
Alle Dateien aus Google Drive in einen Vector Store laden und per Chat durchsuchen. Der AI Agent findet relevante Stellen aus hunderten von Seiten in Sekunden. Ideal für Content Creator und Selbstständige mit vielen PDFs und Notizen.
Support-Wissensbasis
Ein Retrieval-Workflow schlägt bei eingehenden Support-Anfragen automatisch passende Antworten aus dem Produkthandbuch vor. Standardfragen werden vollautomatisch beantwortet, komplexe Fälle eskaliert der Agent weiter.
n8n RAG Troubleshooting: Falsche Antworten beheben
Ungenaue Antworten sind das häufigste Problem bei RAG-Systemen. Meistens liegt es nicht am Sprachmodell, sondern an der Qualität der Chunks oder der Konfiguration des Retrievals.
Der Agent gibt zu vage oder allgemeine Antworten
Ursache: Die Chunks sind zu groß und enthalten zu viel Kontext auf einmal. Der Retriever findet die richtigen Abschnitte, aber das Modell kann die relevante Stelle nicht herausarbeiten. Lösung: Chunk-Größe auf 300 bis 400 Tokens reduzieren und den Ingestion-Workflow neu durchlaufen lassen.
Der Agent findet die relevanten Inhalte nicht
Ursache 1: Top-K ist zu niedrig. Wenn nur 1 oder 2 Chunks übergeben werden, reicht der Kontext nicht. Top-K auf 4 bis 6 erhöhen. Ursache 2: Das Embedding-Modell im Retrieval-Workflow stimmt nicht mit dem aus dem Ingestion-Workflow überein. Beide Workflows müssen identische Embeddings verwenden.
Deutsche Texte werden schlecht verstanden
OpenAI text-embedding-3-small funktioniert auch für Deutsch gut. Wenn die Ergebnisse trotzdem schwach sind, liegt es oft an der Dokumentqualität: gescannte PDFs ohne OCR oder schlecht formatierte Texte produzieren unbrauchbare Chunks. Vorher mit einem Text-Extraktor die Qualität prüfen. Für rein deutschsprachige Inhalte ist Cohere Multilingual eine starke Alternative.
Die Antworten sind veraltet, obwohl die Dokumente aktualisiert wurden
Der Vector Store enthält noch die alten Chunks. Entweder den Vector Store komplett leeren und den Ingestion-Workflow neu starten, oder einen differenziellen Update-Mechanismus einbauen: nur geänderte Dokumente neu einlesen und die alten Chunks für diese Dokument-IDs vorher löschen.
Der Ingestion-Workflow schlägt bei großen Dokumenten fehl
n8n hat ein Standard-Dateilimit für Binary-Daten. Bei großen PDFs den Workflow auf Batch-Verarbeitung umstellen: Dokument in Seiten aufteilen und Seite für Seite verarbeiten. Alternativ die maximale Payload-Größe in den n8n-Einstellungen erhöhen.
Wenn keines dieser Probleme zutrifft, lohnt sich ein Blick in die n8n Community. Viele RAG-spezifische Probleme sind dort bereits diskutiert und mit konkreten Workflow-Anpassungen gelöst.
DSGVO: Wo landen deine Daten im RAG-System?
Das ist die Frage, die in keinem englischsprachigen Artikel gestellt wird. Für deutsche Selbstständige und Unternehmen ist sie aber zentral.
In einem typischen Cloud-RAG-System mit Supabase und OpenAI verlassen deine Dokumente deinen Rechner zweimal: beim Embedding-Aufruf an die OpenAI API und beim Speichern im Supabase Vector Store. Beide Anbieter bieten EU-Optionen, OpenAI verarbeitet Daten aber grundsätzlich auf US-Servern.
Für unkritische Inhalte (öffentliche Dokumente, Produktbeschreibungen, allgemeine FAQ) ist das kein Problem. Supabase mit EU-Region (Frankfurt) und OpenAI Embeddings sind eine solide Kombination.
Für sensible Inhalte (Kundendaten, interne Prozesse, vertrauliche Dokumente) empfiehlt sich das vollständig lokale Setup:
- Qdrant selbst gehostet via Docker
- Embeddings via Ollama (lokal auf deinem Rechner)
- Kein Datentransfer nach außen
Wie du Ollama mit n8n verbindest, zeigt die Anleitung zu n8n + Ollama. Das lokale Setup lässt sich direkt für RAG verwenden: Ollama stellt das Embedding-Modell bereit, Qdrant übernimmt den Vector Store. Alle DSGVO-Anforderungen für n8n-Workflows im Detail erklärt der Artikel n8n und DSGVO.
Fazit: Wann lohnt sich ein n8n RAG-System?
Ein RAG-System in n8n ist keine Raketenwissenschaft. Die Bausteine sind vorhanden, die Templates erledigen die Grundkonfiguration, und das erste System läuft in ein bis zwei Stunden.
Der entscheidende Unterschied zu anderen RAG-Frameworks: Du brauchst kein Python, kein LangChain, keine Entwicklungsumgebung. Wer n8n bereits für andere Workflows nutzt, kann sein RAG-System nahtlos integrieren, ob als Chatbot, als Bestandteil eines größeren Automatisierungs-Workflows oder als interne Wissensdatenbank für ein Team.
Empfehlung für den Einstieg: Supabase Free + OpenAI Embeddings + ein n8n-Template aus der RAG-Kategorie. Damit bist du in unter zwei Stunden live.
Empfehlung für sensible Daten: Qdrant via Docker + Ollama-Embeddings. Komplett lokal, kein Datentransfer, DSGVO-konform.
Wer noch kein n8n-Konto hat, kann es hier kostenlos testen. Mehr zu KI-Agenten in n8n gibt es in der Anleitung zum n8n KI-Agenten bauen. Das lokale Modell-Setup erklärt n8n + Ollama. Wie Claude direkt in n8n-Workflows eingreift, zeigt der Artikel zum n8n MCP Server. Den vollständigen Überblick über n8n liefert die n8n Übersichtsseite.
Häufige Fragen zu RAG in n8n
Brauche ich Programmierkenntnisse für ein n8n RAG-System?
Nein. n8n verbindet alle nötigen Bausteine visuell per Node-Editor. Du konfigurierst Chunk-Größen, wählst Modelle und verbindest Nodes per Drag-and-Drop. Für fortgeschrittene Setups mit eigener Logik hilft ein Code Node, ist aber kein Pflichtbestandteil.
Was kostet ein RAG-System mit n8n im Monat?
Das hängt vom Umfang ab. Für ein kleines System mit Supabase Free Plan und OpenAI text-embedding-3-small sind die laufenden Kosten minimal: einige Cent pro 1.000 Seiten beim Einlesen, Bruchteile davon bei jeder Suchanfrage. n8n selbst ist kostenlos bei selbstgehostetem Betrieb. Das lokale Setup mit Qdrant und Ollama hat nach der einmaligen Einrichtung keine variablen Kosten.
Kann das RAG-System auch mit deutschen Texten umgehen?
Ja. OpenAI Embeddings (text-embedding-3-small) sind mehrsprachig und funktionieren gut mit deutschen Texten. Für rein deutschsprachige Anwendungen kann Cohere Multilingual bessere Ergebnisse liefern. Das Sprachmodell, das die Antworten generiert, muss ebenfalls Deutsch beherrschen: GPT-4o, Claude und aktuelle Mistral-Modelle tun das ohne weitere Konfiguration.
Wie viele Dokumente kann ein n8n RAG-System verarbeiten?
Das Limit setzt der Vector Store, nicht n8n. Supabase Free erlaubt bis zu 500 MB Daten, was mehreren Tausend Seiten entspricht. Qdrant und Pinecone skalieren deutlich weiter. Für die meisten Einsatzszenarien von Selbstständigen und kleinen Teams reicht Supabase Free problemlos.
Was ist der Unterschied zwischen einem normalen KI-Agenten und einem RAG-Agenten?
Ein normaler AI Agent antwortet aus dem trainierten Wissen des Modells. Ein RAG-Agent durchsucht vor jeder Antwort eine Wissensdatenbank und antwortet auf Basis der gefundenen Inhalte. Der RAG-Agent halluziniert deutlich weniger bei spezifischen Fragen und liefert aktuelle Informationen, die nicht im Training des Modells enthalten sind.
Schreibe einen Kommentar