


Willkommen im unsichtbaren Universum der „Token“, wo jedes einzelne Wort zählt. Hier erfährst du, wie Token die Brücke zwischen menschlicher Sprache und künstlicher Intelligenz schlagen. Erfahre, wie die Token funktionieren.
Inhaltsverzeichnis
Was sind Token bei KI?
Token sind die grundlegende Einheit für alle gängigen KI-Modelle, egal ob ChatGPT, Gemini, Copilot oder Claude. Mit dem Token wird die Länge eines Texts bestimmt. Auch für die Bezahlung ist die Zahl der Token relevant, wenn du einen API-Zugang benutzt. Hier werden häufig die verbrauchten Token einzeln abgerechnet. Daneben werden Token genutzt, um den Text zu „verstehen“ und die Antwort auf die Nutzeranfrage zu liefern.
Die Anzahl der Token hängt davon ab:
- welche Sprache genutzt wird,
- wie lang der Text ist,
- welches KI-Modell du nutzt,
- ob es sich um Satzzeichen (.,:;?!) oder
- ob es sich um Emojis (😀😄😂) handelt.
Es gibt keine feste Umrechnung von Text in Token oder zurück. Teilweise verbrauchen einzelne Buchstaben eines Wortes zusätzlich Token.
Woher weiß ich, wie viele Token mein Text verbraucht?
Von OpenAI gibt es einen Tokenizer, den du für die Analyse benutzen kannst. Mit diesem kannst du die Token der verschiedenen Sprachmodelle von ChatGPT-4o bis zu ChatGPT 3 analysieren.
Das neuste Modell OpenAI o1 steht aktuell noch nicht zur Auswahl. Die Besonderheit des Modells ist, dass es „denken kann“ und Aufgaben schrittweise lösen kann. Für den Denkprozess werden intern zusätzlich Token verbraucht, auch wenn du die Ergebnisse des Denkprozesses nicht siehst. Wichtig für Nutzer der API Schnittstelle – auch diese Token werden abgerechnet.
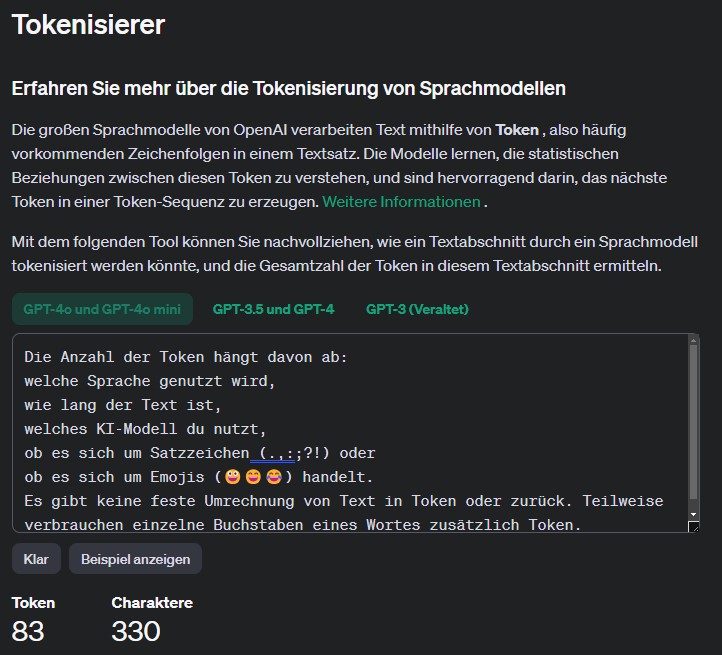
Der Beispieltext hat 330 Zeichen. Unter ChatGPT 3 wurden noch 134 Token und unter ChatGPT-o4 und ChatGPT-o4 mini werden 83 Token berechnet. Immerhin ein Unterschied von 38 %.
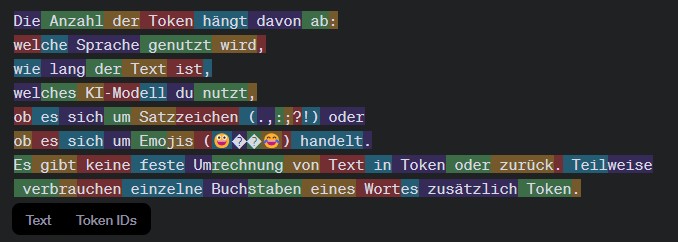
Bei jedem Farbwechsel wird ein weiterer Token gezählt. Für das Wort „verbrauchen“ in der letzten Zeile werden z. B. 3 Token verbraucht. Insgesamt sind es 83 Token.
Dass die Anzahl der Token je nach Sprache unterschiedlich ist, zeigt der folgende Test:

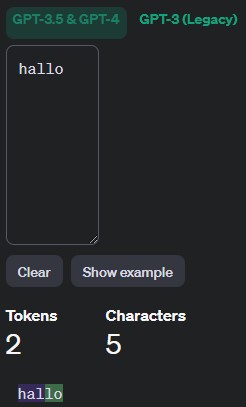
Beide Wörter haben 5 Zeichen. Die Bedeutung von „hello“ im englischen und „hallo“ sind identisch. Dennoch verbraucht „hallo“ 2 Token statt 1 Token.
Um das Verhältnis zwischen Token und Wörtern im Deutschen abzuschätzen, habe ich den Osterspaziergang von Goethe verwendet. Das Gedicht hat 215 Wörter. Der Tokenizer hat mit ChatGPT-4o und ChatGPT-4o mini 376 Token ermittelt.
Pro Wort werden somit 1,75 Token gezählt.
Das entspricht ungefähr dem Verhältnis, was du als Erfahrungswert im Netz an verschiedenen Stellen findest. Dort werden pro Wort in Deutsch zwischen 1,5 und 1,8 Token genannt. Allerdings entspricht der Osterspaziergang nicht mehr unserem aktuellen Sprachgebrauch. Auch sind keine Smileys enthalten. Als Näherung kannst du mit dem Faktor von 1 : 1,75 bei ChatGPT-4o und 4o-mini rechnen.
Wie werden Token bei der Verarbeitung von Text genutzt?
Wenn du bei einer KI einen Text eingibst, wird deine Eingabe in Token zerlegt. In den Trainingsdaten wird auf Basis der Token-IDs nach der Antwort gesucht. Die Antwort wird zurückübersetzt und dem Anwender die Antwort angezeigt.
Dabei ist die Künstliche Intelligenz nicht wirklich intelligent. Die Antwort wird auf Grundlage erlernter Wahrscheinlichkeiten generiert. Der nächste Token wird anhand des vorherigen Tokens ausgewählt. Durch die extrem umfangreichen Trainingsdaten bekommst du „sinnvolle“ Antworten. Das System arbeitet nicht auf Ebene von Buchstaben oder Wörtern. Das ist auch der Grund, warum KI manchmal Schwierigkeiten mit der Rechtschreibung hat.
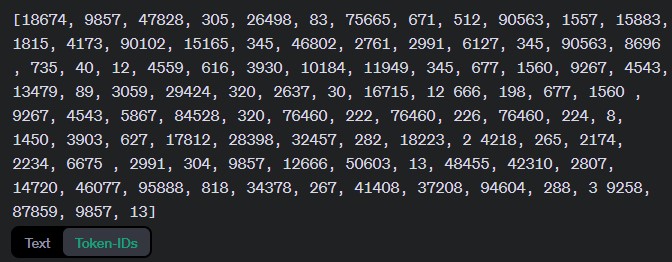
Die Token-ID sind die „interne Sprache“ von ChatGPT. In dem Beispiel siehst du die Darstellung des Beispieltextes. Wenn es sich um einen Prompt handeln würde, würde auf dieser Ebene die Antwort generiert.
Schreibe einen Kommentar