


Das Wichtigste auf einen Blick
- Meta hat drei neue Llama 4 Modelle veröffentlicht: Scout (109 Mrd. Parameter), Maverick (400 Mrd. Parameter) und Behemoth (bis zu 2 Billionen Parameter)
- Alle Modelle nutzen eine Mixture-of-Experts (MoE) Architektur.
- Llama 4 Scout bietet ein riesiges Kontextfenster von 10 Millionen Token – weit mehr als GPT-4 und andere Konkurrenten
- Die Modelle sind von Grund auf multimodal und können Text und Bilder verarbeiten
- Für Nutzer und Unternehmen mit Sitz in der EU gelten Einschränkungen bei der direkten Nutzung
Inhaltsverzeichnis
Llama 4: Metas neue KI-Generation im Überblick
Meta hat im April 2025 seine neueste Generation KI Modellen vorgestellt: Llama 41. Die Modelle setzen auf eine Mixture-of-Experts (MoE) Architektur. Dabei wird die Anfrage an spezielle Experten innerhalb des Modells geleitet. So muss bei einer Anfrage nur ein Bruchteil der Parameter aktiv sein.
Es gibt drei neuen Modelle – Scout, Maverick und Behemoth. Sie unterscheiden sich in der Größe und ihren Spezialisierungen. Alle sind multimodal aufgebaut und können sowohl Text als auch Bilder verarbeiten. Bemerkenswert ist das enorme Kontextfenster von Llama 4 Scout, das bis zu 10 Millionen Token umfassen kann. Ein gewaltiger Sprung gegenüber bisheriger Modelle.
Die Llama 4 Modelle im Detail
Klicke auf die Karten, um mehr Details zu erfahren.
• 16 Experten in MoE-Architektur
• 10 Millionen Token Kontextfenster
• Trainiert mit ~40 Billionen Tokens
• Läuft auf High-End-Hardware (z.B. H100 GPU)
• Benötigt 55-60 GB RAM bei 4-Bit-Quantisierung
• Multimodal: Text und Bilder
• 128 Experten in MoE-Architektur
• 1 Million Token Kontextfenster
• Trainiert mit ~22 Billionen Tokens
• Benötigt mehrere GPUs oder DGX-Host
• Optimiert für Reasoning und multimodale Aufgaben
• Exzelliert bei Bildverständnis und kreativen Aufgaben
• 16 Experten (jeder mit enormer Kapazität)
• Kontextfenster bisher nicht spezifiziert
• Trainiert mit ~30 Billionen Tokens
• Nur auf spezialisierten Rechenclustern lauffähig
• Optimiert für wissenschaftliche und MINT-Anwendungen
• Übertrifft GPT-4.5 und Claude 3.7 in mathematischen Benchmarks
• Noch in Entwicklung (Stand April 2025)
Llama 4 Scout
Llama 4 Scout richtet sich an Anwender, die ein ausgewogenes Verhältnis zwischen Leistungsfähigkeit und Effizienz suchen. Mit insgesamt 109 Milliarden Parametern und 16 Experten nutzt Scout bei jeder Anfrage nur etwa 17 Milliarden aktive Parameter.
Die wichtigsten Eigenschaften von Llama 4 Scout:
- 109 Milliarden Gesamtparameter
- 16 Experten in der MoE-Architektur
- Kontextfenster von bis zu 10 Millionen Token
- Läuft auf High-End-Hardware wie einer einzelnen H100 GPU
- Benötigt etwa 55-60 GB RAM
Das beeindruckendste Merkmal von Scout ist das gigantisches Kontextfenster. Mit 10 Millionen Token kann es theoretisch etwa 7.500 Seiten Text auf einmal verarbeiten – das entspricht mehreren Romanen oder hunderten wissenschaftlichen Artikeln gleichzeitig. Diese Fähigkeit macht Scout besonders wertvoll für Anwendungen wie Dokumentenanalyse, juristische Textverarbeitung oder die Arbeit mit großen Programmcode.
Llama 4 Maverick
Das zweite Modell in der Llama 4-Familie ist Maverick – ein deutlich größeres System, das auf kreative und komplexe Aufgaben spezialisiert ist.
Die wichtigsten Eigenschaften von Llama 4 Maverick:
- 400 Milliarden Gesamtparameter
- 128 Experten in der MoE-Architektur
- Kontextfenster von bis zu 1 Millionen Token
- Läuft auf mehreren GPUs oder einem DGX-Host
Maverick setzt auf eine größere Anzahl von Experten (128 statt 16). Dies erlaubt dem Modell, aus einem viel größeren Wissenspool zu schöpfen, ohne die Rechenanforderungen drastisch zu erhöhen.
Das Modell exzelliert besonders bei Reasoning-Aufgaben und multimodalen Anwendungen. Es kann komplexe Bilder analysieren, kreative Inhalte erstellen und anspruchsvolle Probleme lösen. In Benchmarks für Bildverständnis und logisches Denken erzielt Maverick regelmäßig bessere Ergebnisse als Scout.
Der Preis für diese Leistung ist ein deutlich höherer Hardwarebedarf – Maverick benötigt meist mehrere GPUs oder einen DGX-Host und eignet sich daher vorwiegend für mittlere bis große Unternehmen oder Cloud-Anbieter.
Llama 4 Behemoth
Behemoth ist das Flaggschiff der Llama 4-Serie und befindet sich noch in der Entwicklung (Stand April 2025). Mit bis zu 2 Billionen Gesamtparametern und 288 Milliarden aktiven Parametern übertrifft es alle bisherigen öffentlich verfügbaren Modelle deutlich.
Meta positioniert Behemoth als “Lehrermodell” für wissenschaftliche und hochkomplexe Aufgaben:
- 2 Billionen Gesamtparameter (geschätzt)
- 288 Milliarden aktive Parameter
- 16 Experten (jeder mit enormer Kapazität)
- Trainiert mit ca. 30 Billionen Tokens
- Spezialisiert auf MINT-Fächer, wissenschaftliche Aufgaben und Mehrsprachigkeit
In vorläufigen Benchmarks übertrifft Behemoth angeblich sowohl GPT-4.5 als auch Claude Sonnet 3.7 und Gemini 2.0 Pro in mathematischen und wissenschaftlichen Tests. Auf dem MATH-500 Benchmark erreicht es beeindruckende 95,0 Punkte, verglichen mit 91,8 für Gemini 2.0 Pro und 82,2 für Claude Sonnet 3.7.
Aufgrund seiner enormen Größe wird Behemoth vermutlich nur auf spezialisierten Rechenclustern laufen können und nicht für den typischen Endnutzer zugänglich sein. Es ist wahrscheinlich, dass Meta dieses Modell primär für Forschungszwecke und als Basis für kleinere, distillierte Modelle einsetzen wird.
Mixture-of-Experts: Die Architektur hinter Llama 4
Llama 4 nutzt eine Mixture-of-Experts (MoE) Architektur. Diese Methode unterscheidet sich grundlegend von den “dichten” Modellen früherer Generationen.
In einem traditionellen LLM sind bei jeder Anfrage alle Parameter aktiv. Bei einer MoE-Architektur wie in Llama 4 wird hingegen für jedes Token ein “Router” aktiviert, der entscheidet, welche Experten (Teilnetzwerke) für die Verarbeitung zuständig sind. Nur diese ausgewählten Experten werden dann tatsächlich aktiviert.
Dadurch können Modelle viel größer skaliert werden, ohne dass die Rechenanforderungen proportional mitwachsen. Bei Llama 4 Scout sind beispielsweise nur etwa 16% der Gesamtparameter aktiv, bei Maverick sogar nur etwa 4%.
Vorteile der MoE-Architektur:
- Effizienz: Trotz enormer Gesamtgröße bleibt die Inferenzgeschwindigkeit hoch
- Spezialisierung: Experten können sich auf bestimmte Domains oder Aufgaben konzentrieren
- Skalierbarkeit: Ermöglicht viel größere Modelle bei gleichen Ressourcen
- Bessere Generalisierung: Mehr Parameter bedeuten mehr Wissen, das abgerufen werden kann
Diese Architektur erlaubt es Meta, mit deutlich größeren Modellen zu experimentieren, ohne dass die Hardwareanforderungen unerfüllbar werden. Mit nur 17 Milliarden aktiven Parametern können die Modelle auf viel mehr Wissen zugreifen als herkömmliche Architekturen erlauben würden.
Wie schneidet Llama 4 im Vergleich zur Konkurrenz ab?
Nach Metas Angaben und ersten Benchmarks zeigt sich ein durchwachsenes Bild.
Llama 4 Scout vs. Llama 3.3 70B
- Kontextfenster: Scout übertrifft mit 10 Millionen Token Llama 3.3 (128.000) um das 78-fache
- Effizienz: Bei vergleichbarer Leistung benötigt Scout weniger Rechenressourcen
- Multimodalität: Scout ist multimodal, Llama 3.3 primär textbasiert
Scout schint insbesondere bei langen Kontexten zu glänzen, während die Reasoning-Fähigkeiten im Vergleich zu Llama 3.3 nicht dramatisch besser sind. Die Effizienz und Multimodalität sind jedoch klare Fortschritte.
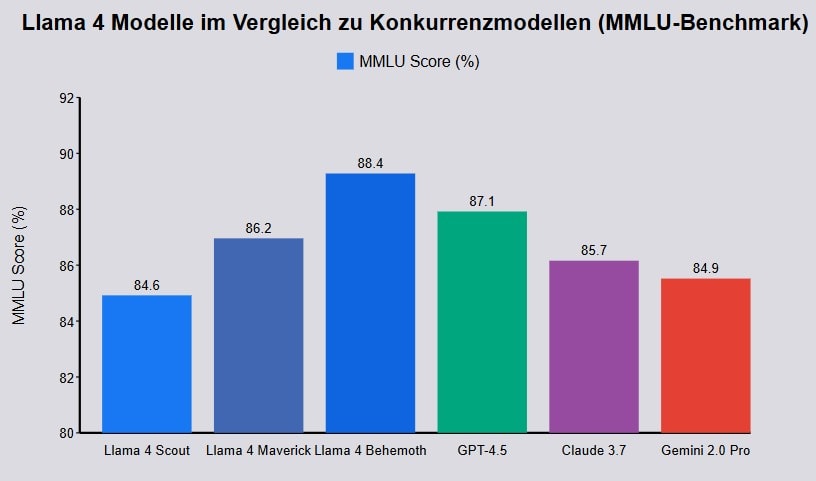
Llama 4 Maverick vs. GPT-4.5 und Claude Sonnet 3.7
Maverick zeigt in verschiedenen Benchmarks konkurenzfähige Ergebnisse:
| Benchmark | Maverick | GPT-4.5 | Claude 3.7 | Gemini 2.0 Pro |
|---|---|---|---|---|
| MMLU | 86.2 | 87.1 | 85.7 | 84.9 |
| MMMU (Multimodal) | 76.1 | 74.4 | 72.8 | 73.5 |
| LiveCodeBench | 49.4 | 47.8 | 42.3 | 36.0 |
Maverick scheint bei multimodalen Aufgaben und Codierung besonders stark zu sein, während es bei allgemeinem Wissen (MMLU) leicht hinter GPT-4.5 zurückbleibt.
Llama 4 Behemoth vs. Top-Modelle
Behemoth übertriff laut Meta die meisten anderen Modelle in wissenschaftlichen und mathematischen Benchmarks:
- MATH-500: 95.0 (vs. 91.8 für Gemini 2.0 Pro und 82.2 für Claude 3.7)
- GPQA Diamond: 73.7 (vs. 71.4 für GPT-4.5)
- Multilingual MMLU: 85.8 (vs. 85.1 für GPT-4.5)
Diese Ergebnisse sind beeindruckend, müssen jedoch noch durch unabhängige Tests bestätigt werden. Meta positioniert Behemoth klar als Spitzenmodell für wissenschaftliche Anwendungen und komplexes Reasoning.
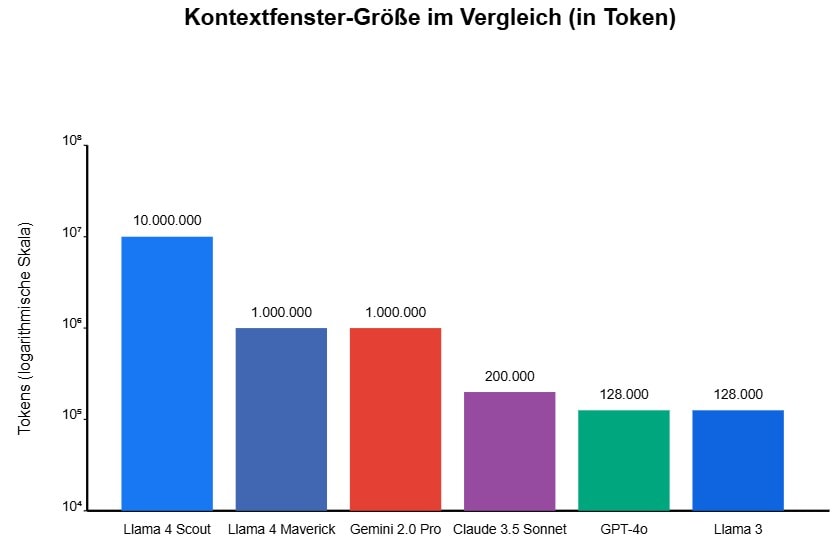
Kontextfenster: Unglaubliche 10 Millionen Token
Eine der bemerkenswertesten Innovationen von Llama 4 ist das enorme Kontextfenster von Scout. Mit 10 Millionen Token übertrifft es alle gängigen Modelle um Größenordnungen:
- GPT-4o: 128.000 Token
- Claude 3.5 Sonnet: 200.000 Token
- Gemini 2.0 Pro: 1 Million Token
- Llama 4 Scout: 10 Millionen Token
Dieses riesige Kontextfenster eröffnet völlig neue Anwendungsmöglichkeiten:
- Analyse ganzer Bücher oder Gesetzestexte auf einmal
- Verarbeitung kompletter Codebases ohne Aufspaltung
- Multi-Dokument-Vergleiche mit Dutzenden oder Hunderten von Dokumenten
- Langfristige Konversationen ohne Gedächtnisverlust
Multimodale Fähigkeiten der Llama 4-Modelle
Anders als frühere Llama-Versionen sind die neuen Modelle multimodal.
Diese nativ multimodale Architektur ermöglicht:
- Nahtlose Integration von Text und Bildern
- Verbessertes Bildverständnis verglichen mit nachträglich ergänzten Bildverarbeitungsmodulen
- Detaillierte Bildanalyse einschließlich komplexer visueller Reasoning-Aufgaben
- Zukünftige Erweiterungen für Video und andere Modalitäten
In Benchmarks für visuelles Reasoning wie MMMU erreicht insbesondere Maverick beeindruckende Ergebnisse (76.1) und übertrifft GPT-4o (74.4) und andere führende multimodale Modelle.
Die Architektur basiert auf dem Konzept der “frühen Fusion” (Early Fusion), bei der Bild- und Textinformationen schon in frühen Verarbeitungsschichten gemeinsam verarbeitet werden. Dies unterscheidet sich von anderen Ansätzen, die separate Encoder für verschiedene Modalitäten verwenden und deren Ausgaben erst spät kombinieren.
Nutzung und Einschränkungen von Llama 4
Verfügbarkeit der Modelle
Llama 4 Scout und Maverick sind ab sofort verfügbar, während Behemoth noch in der Entwicklung ist. Die Modelle können auf verschiedene Weise genutzt werden:
- Lokale Installation: z. B. direkt von llama.com
- Cloud-Dienste: Verschiedene Anbieter integrieren die Modelle in ihre Dienste. So kannst du Scout und Maverik bei OpenRouter bereits benutzen.
Für den lokalen Betrieb von Scout werden mindestens 55-60 GB RAM empfohlen, idealerweise eine leistungsstarke GPU wie eine NVIDIA H100. Da muss ich persönlich passen. Über solch eine Hardware verfüge ich nicht.
Llama 4 Hardware-Rechner
Lizenzeinschränkungen
Eine wichtige Einschränkung betrifft Nutzer und Unternehmen in der Europäischen Union:
“Die multimodalen Modelle von Llama 4 […] dürfen weder von Individuen noch von Unternehmen mit Sitz in der Europäischen Union genutzt werden.”
Diese Einschränkung gilt für die direkte Nutzung der Modelle, nicht jedoch für Endnutzer, die Dienste oder Produkte verwenden, die auf Llama 4 basieren.
Die Gründe für diese Einschränkungen liegen vermutlich in den strengen Datenschutz- und Urheberrechtsbestimmungen der EU sowie möglichen regulatorischen Herausforderungen durch den AI Act.
Wie kann man Llama dennoch direkt bei Meta nutzen? Verwende einen VPN wie z. B. ProtonVPN oder NordVPN.
Anwendungsfälle für Llama 4
Die Llama 4 Modelle eignen sich für unterschiedliche Anwendungsfälle:
Llama 4 Scout:
- Dokumentenanalyse großer Textmengen
- Codeanalyse und -generierung für umfangreiche Projekte
- Recherche-Assistenten mit großer Wissensbasis
Llama 4 Maverick:
- Kreative Inhalterstellung mit Bild und Text
- Komplexes Reasoning für Entscheidungsunterstützung
- Bildanalyse und -beschreibung
- Interaktive multimodale Assistenten
Llama 4 Behemoth (zukünftig):
- Wissenschaftliche Forschung in MINT-Fächern
- Komplexe mathematische Probleme
- Mehrsprachige Anwendungen mit hoher Präzision
- Knowledge Distillation für kleinere Modelle
Durch das modulare Design könn Entwickler und Unternehmen das für ihren Anwendungsfall am besten geeignete Modell auswählen, anstatt immer auf das größte verfügbare Modell zurückgreifen zu müssen.
Technischer Vergleich: Llama 4 vs. Llama 3
Die Llama 4 Modelle unterscheiden sich deutlich von ihren Vorgängern:
| Feature | Llama 3 | Llama 4 |
|---|---|---|
| Architektur | Dicht (Dense) | Mixture-of-Experts (MoE) |
| Max. Gesamtparameter | 405 Mrd. | Bis zu 2 Billionen |
| Aktive Parameter | Alle | 17 Mrd. (Scout/Maverick) |
| Kontextfenster | 128.000 Tokens | 10 Mio. Tokens (Scout) |
| Multimodalität | Text | Native Text-, Bild- & Videodaten |
| Vision-Encoder | Nicht integriert | MetaCLIP-basiert, Early Fusion |
| Sprachen | ~100 | 200 (über 100 mit >1 Mrd. Tokens) |
| Trainingsdaten | < 15 Billionen Tokens | > 30 Billionen Tokens |
Llama 4 übertrifft seine Vorgänger in praktisch allen Aspekten, wobei die Einführung von Mixture-of-Experts und die erhebliche Vergrößerung des Kontextfensters nach meiner Meinung die größten Fortschritte darstellen.
Häufig gestellte Fragen zu Llama 4
Was ist der Unterschied zwischen Llama 4 Scout, Maverick und Behemoth?
Scout (109 Mrd. Parameter) ist für Effizienz und lange Kontexte optimiert, Maverick (400 Mrd. Parameter) für komplexes Reasoning und multimodale Aufgaben, und Behemoth (ca. 2 Billionen Parameter) wird ein Spitzenmodell für wissenschaftliche Anwendungen sein.
Kann ich Llama 4 auf meinem PC nutzen?
Die Llama 4 Modelle haben sehr hohe Anforderungen an deine Hardware. Erfüllst du diese, kannst du das Modell deiner Wahl lokal nutzen. Andernfalls empfehle ich dir das Modell online zu nutzen. In Europa zum Beispiel mit OpenRouter oder direkt bei Meta, wofür du jedoch einen VPN brauchst. Hierfür kannst du ProtonVPN oder NordVPN nutzen
Ist Llama 4 wirklich besser als GPT-4 oder Claude 3?
In einigen Bereichen ja, in anderen nein. Llama 4 Scout übertrifft andere Modelle beim Kontextfenster deutlich, während Maverick und besonders Behemoth in wissenschaftlichen und mathematischen Benchmarks stark abschneiden. Bei allgemeinem Wissen und einigen Reasoning-Aufgaben liegen GPT-4.5 und Claude teils noch vorn.
Darf ich Llama 4 in der EU nutzen?
Was bedeutet Mixture-of-Experts (MoE)?
MoE ist eine Architektur, bei der das Modell aus mehreren “Experten” (Teilnetzwerken) besteht, von denen für jedes Token nur einige aktiviert werden. Deine Anfrage wird vom jeweilig bestgeeigneten Experten bearbeitet und nicht vom kompletten Netzwerk. Dies ermöglicht viel größere Modelle bei gleichbleibender Recheneffizienz.
Wie kann ich mit dem 10-Millionen-Token-Kontextfenster arbeiten?
Das riesige Kontextfenster von Scout erlaubt es, sehr große Dokumente auf einmal zu verarbeiten. Du kannst beispielsweise ganze Bücher, Gesetzestexte oder Programmcode laden und Fragen dazu stellen.
Wird es auch kleinere Llama 4 Modelle geben?
Meta hat angekündigt, dass später auch kleinere Modelle folgen werden, vermutlich mit 8B, 20B und 70B Parametern, ähnlich wie bei früheren Llama-Versionen.
Kann man Llama 4 für kommerzielle Zwecke nutzen?
Ja. Einschränkungen gibt es für Unternehmen mit mehr als 700 Millionen monatlich aktiven Nutzern. Diese benötigen eine Sondergenehmigung von Meta.
Schreibe einen Kommentar